Není to žádná novinka, nicméně já se o funkcích pro import dat z webových stránek do tabulek v Google Docs dozvěděl až nedávno (nebo jsem na ně spíše od doby jejich uvedení zapomněl). Předpokládám, že takových nás bude víc, proto přijměte malou připomínku těchto funkcí.
Import tabulek a seznamů do Google Docs – kurzy měn z webu ČNB
Základní funkcí pro získávání dat z webových stránek je ImportHTML(). Stejně jako všechny další funkce ji v tabulkách Google Docs použijete tak, že do prázdné buňky napíšete =ImportHTML(). Do závorky přitom uvedete argumenty této funkce.
ImportHTML() očekává specifikaci tří argumentů oddělených středníkem. Jako první je potřeba zadat URL adresu, ze které chcete data vytáhnout. Druhým argumentem pak je selektor, určující prvek na stránce, jehož data chcete do tabulky načíst. A konečně poslední argument je číslo udávající pořadí daného prvku na stránce, pokud se jich tam nachází více.
Jako druhý argument pro funkci ImportHTML() můžete použít výraz table nebo list. První slouží pro zpracování tabulek (HTML značka <table>) na stránce, druhý prochází seznamy (v HTML <ul> nebo <ol>).
Ukážeme si to na praktickém příkladu. Na webu České národní banky je k dispozici vždy aktuální kurz měn. HTML tabulek je ve struktuře stránky více, ta s kurzy měn je druhá v pořadí. Příslušná část webové stránky vypadá takto:
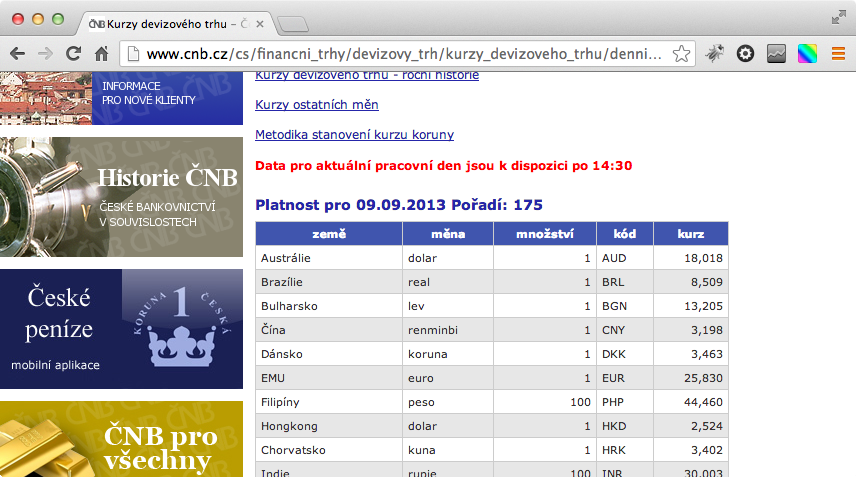
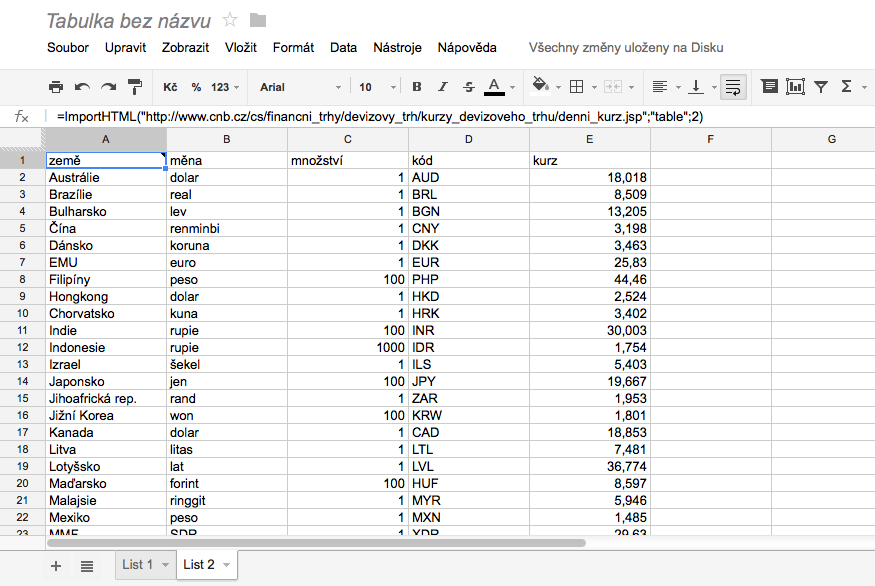
Známe tedy adresu, víme, co z ní chceme získat a víme, kolikátá tabulka na stránce kurzy měny jsou. Otevřete si tedy Google Docs a vyberte vytvoření nového sešitu s tabulkou. Do buňky A1 pak zadejte následující:
=ImportHTML("http://www.cnb.cz/cs/financni_trhy/devizovy_trh/kurzy_devizoveho_trhu/denni_kurz.jsp";"table";2)
Po chviličce zpracovávání by se vám tabulka z ČNB měla přenést do Google Docs, kde se ní můžete dále běžným způsobem pracovat.
Import XML a parsování webové stránky
Funkce ImportHTML() je určena pouze pro zpracování tabulek a seznamů na stránce. Jestliže chcete provést nějaké pokročilejší zpracování dat ze zadané adresy, budete potřebovat funkci ImportXML(). Ta používá dva argumenty. První je opět URL adresa zdroje, který chcete zpracovat, druhý pak specifikace elementu v syntaxi XPath.
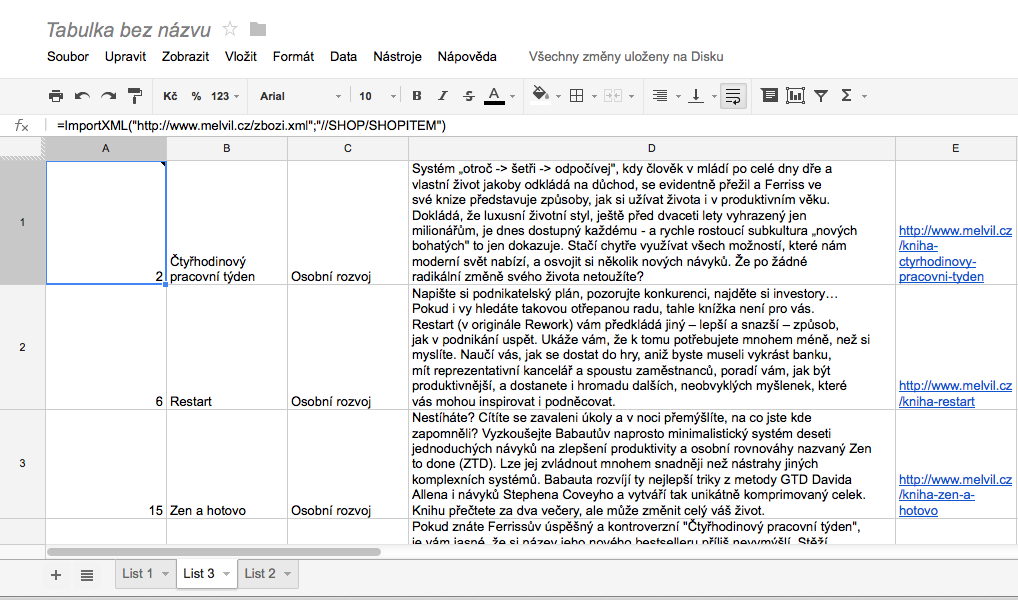
Řekněme, že chceme do tabulky v Google Docs načíst všechny položky z nějakého feedu pro Zboží.cz. Pak by zápis funkce ImportXML() vypadal nějak takto:
=ImportXML("http://www.melvil.cz/zbozi.xml";"//SHOP/SHOPITEM")
Do tabulky se vám vloží veškeré údaje z daného feedu, přičemž na každém řádku bude kompletní informace o jednom nabízeném produktu v daném eshopu.
Pokud by nás zajímaly pouze názvy produktů, zjistíme, jak XML vypadá a budeme vědět, že stačí selektor XPath upravit následovně:
=ImportXML("http://www.melvil.cz/zbozi.xml";"//SHOP/SHOPITEM/PRODUCT")
Takto můžeme jednotlivé sloupce tabulky naplnit jen daty která nás zajímají a rázem získáme kompletní ceník pro daný eshop, aniž bychom museli programovat nějakou novou exportní funkci.
Co je ovšem důležité, funkci ImportXML() lze použít i pro zpracování dat z nějaké běžné webové stránky. Představme si, že budeme chtít získat seznam názvů článků, které se nacházejí na titulní straně Maxiorla:
=Importxml("https://www.maxiorel.cz/";"//div[contains(@class, 'node')]/h2")
Poznámka: //h2 v XPath by nestačilo, protože na stránce mohou být další nadpisy H2, proto tedy procházíme selektorem všechny DIVy obsahující v atributu class výraz node a následně všechny v nich zanořené H2.
Podobně můžete parsovat i výsledky ve vyhledávači. Například získání odkazů na stránky, kde je použit výraz Jan Polzer by zápis vypadal takto (při parsování výsledků na Seznam.cz):
=Importxml("http://search.seznam.cz/?q=Jan+Polzer";"//h3/a/@href")
Funkce ImportXML() i ImportHTML() můžete v rámci jednoho tabulkového dokumentu použít maximálně 50x. I to ale myslím stačí na zajímavé využití dat na webu ve vašich tabulkách. Data vystupující z těchto funkcí můžete samozřejmě začlenit do dalších funkcí, které Google Docs podporuje.
Vyzkoušet můžete také funkci ImportFeed(), která slouží pro zpracování dat z RSS kanálu. Kompletní přehled funkcí, které Google Docs u tabulek podporuje, najdete v dokumentaci.

Tvůrce webů z Brna se specializací na Drupal, WordPress a Symfony. Acquia Certified Developer & Site Builder. Autor několika knih o Drupalu.
Web Development Director v Lesensky.cz. Ve volných chvílích podnikám výlety na souši i po vodě. Více se dozvíte na polzer.cz a mém LinkedIn profilu.
Podobné články





Komentáře k článku

No, pravda, koukám. Seznam totiž od doby, kdy byl tento článek napsán, změnil vizuál výsledků hledání z původního seznamu odkazů pod sebou do podoby dlaždic. Tím došlo také ke změně HTML kódu výsledků hledání. Když si v příkazu upravíte část s XPath, tak vám to zase bude fungovat.

Jak upravit ten xPath pro nový Seznam? Dneska jsem si s tím hrál, ale nedaří se mi výsledky načíst. Vám to jede?
Tak jsem na to koukal a obávám se, že to nepůjde. Zkuste si seznam načíst bez JavaScriptu. Místo výsledků hledání zobrazí jen hlášku, že je potřeba mít zapnutý JS. To samozřejmě funkce ImportXML nemá, takže proto nefunguje, ať už s xPath kouzlíte jakkoli. Jestli má někdo nějaké řešení, sem s ním.
Právě že je to zvláštní. Strávil jsem nad tím několik večerů. Když si zobrazím výsledky Seznamu bez JS, tak se mi normálně vypíší. I když si stránku stáhnu třeba přes curl. Takže v JS by podle mě problém být neměl. Spíš jestli nemá seznam nějakou zmatenou syntaxi stránky, že by se v tom ImportXML nevyznal. Nebo nevíte, nemá ImportXML nějaké omezení na velikost zpracovávaného kódu? Jestli není kód moc dlouhý, že by tam k těm výsledkům nedošel...
Divné, je fakt, že curl to stahuje v pořádku.
Šlo by to použít i na ISIR? Tohle se snažím načíst, ale zatím bez úspěchu. Je tam zřejmě nějaké omezení nebo špatně zadávám Xpath. https://isir.justice.cz:8443/isir_ws/services/IsirPub001/getIsirPub001?C...
Řešil jste prosím někdo automatický update XML pro import do google tabulek?
Stále se mi ukazuje stará verze importu.
Dobrý den, ČNB změnila zobrazování dat a jejich export. Je možné zkopírovat odkaz odkazující na nastavený výběr, např.: http://www.cnb.cz/arad/#/cs/display_link/set_1145__D19955.D23266 Jakým způsobem je možné tuto tabulku importovat do google sheets? Velice děkuji za odpověď. josef.krejci@email.cz
Obávám se, že tohle úplně nepůjde, protože v zdrojovém kód ta tabulka není a dokresluje se dynamicky. Zdraví Honza Polzer
Velice děkuji za zprávu. Škoda, že ČNB změnila systém zobrazování dat. Hezký den Josef Krejčí


Na Seznamu dotaz xpath nefunguje a nejde vyzobnout žádná data.