Pokud se svým webem aktivně pracujete, případně se staráte o weby klientů, čas od času dojdete do situace, kdy narazíte na nefungující odkazy. Možná proto, že jste nechtěně změnili adresu podstránek a nenalinkovali je správně z textů v jiné části webu. Možná proto, že odkazujete na cizí stránky, které již změnili svou strukturu.
Jednoduchý bezplatný program Greeflare vám pomůže takové problémy odhalit. Nalezne nefungující odkazy, ale také obrázky, JavaScript nebo CSS stylesheety, které nejdou načítat. Zkrátka je to takový pohotový nástroj pro kontrolu webu.
Podobných nástrojů je více. V perexu zmíněný Screaming Frog SEO Spider platí za jistý etalon v této oblasti. Ovšem myslím, že Greenflare jej drtivé většině z vás zcela vynahradí. Je zadarmo, bez omezení a funguje na Windows, v Linuxu i macOS.
Jak zkontrolovat odkazy na webu s Greenflare
Po stažení aplikace z webu ji jednoduše nastartujte a před první kontrolou webu se porozhlédněte, jaké volby nabízí ve svých čtyřech záložkách:
Crawl – až si projdete následující nastavení, na tuto kartu se opět vraťte. Zadejte URL adresu domovské stránky webu a spusťte kontrolu.
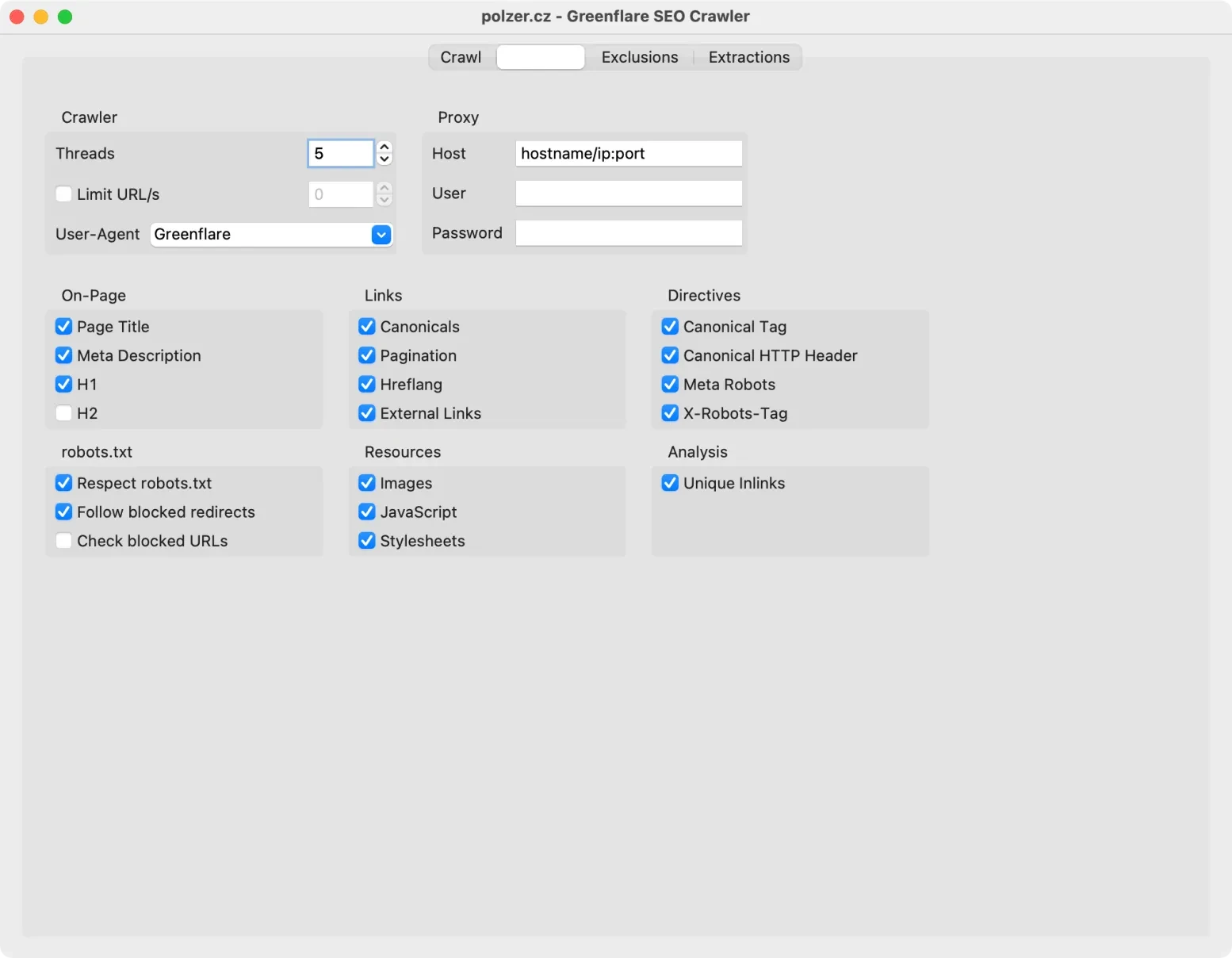
Settings – zde nastavujete, které prvky stránky se budou kontrolovat. Doporučuji zapnout i kontrolu obrázků, CSS a JavaScriptu. Minimálně na macOS nebyla zapnutá.
Exclusions – Greenflare projde automaticky celý web, pokud jej máte správně prolinkovaný. Přesto mohou být adresy, které na webu kontrolovat nechcete. A zde je prostor pro vytvoření jejich seznamu.
Extractions – zde se nabízí prostor pro poněkud nenápadnou, ale za to zajímavou funkci extrakce dat z kontrolovaného webu. O tom později.
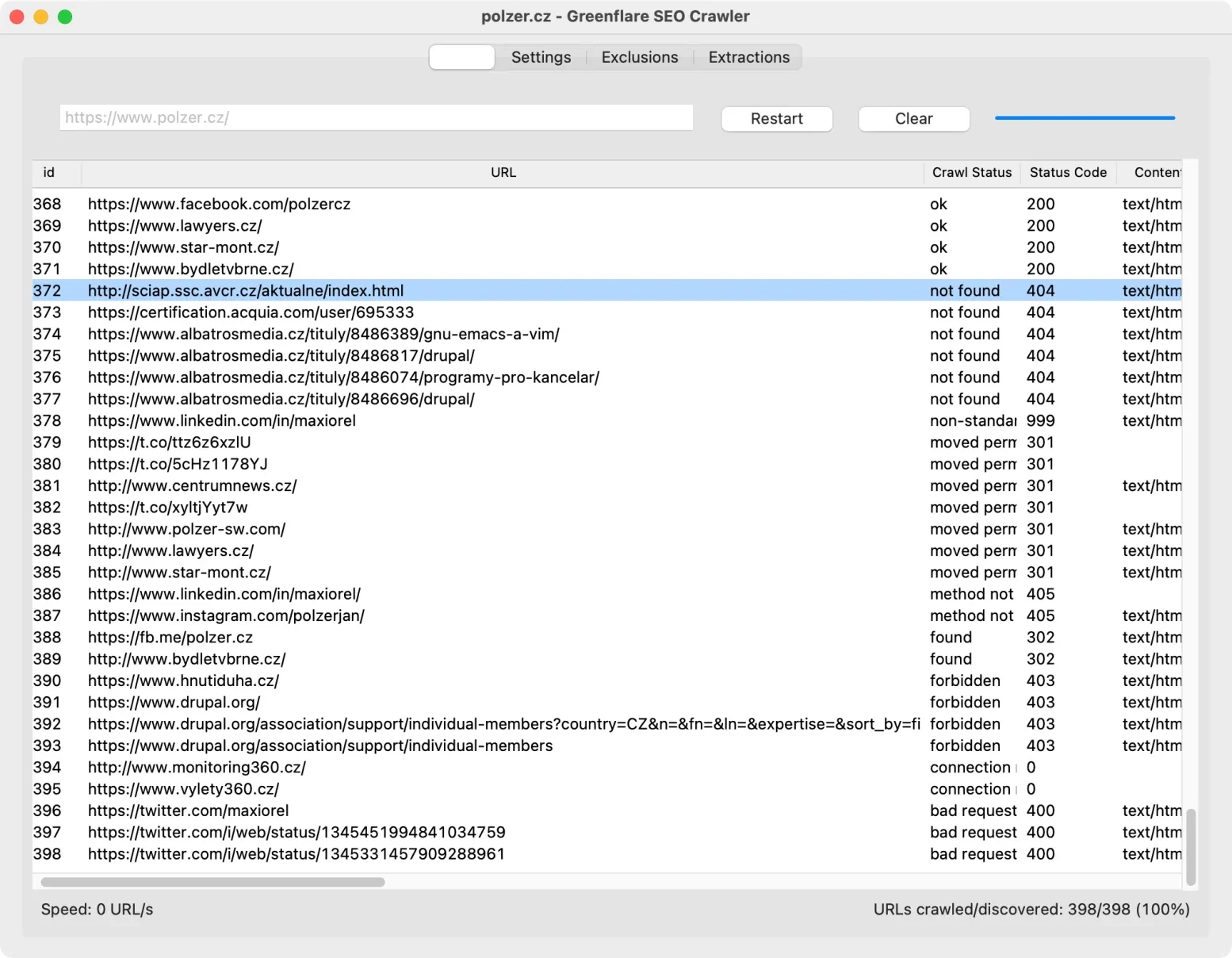
Po spuštění kontroly a jejím dokončení Greenflare vytvoří seznam procházených adres. Podobně jako v konkurenčních aplikacích uvidíte ve sloupečcích slovní stav procházení a číselný kód odpovídající http stavu. Tedy třeba OK 200, Not found 404 a podobně.
Seznam lze seřadit klepnutím pravým tlačítkem myši do záhlaví některého ze sloupečků, případně jej rychle vyfiltrujete podle nějakého kritéria pomocí programové nabídky View. Zobrazený pohled vyexportujete do CSV pomocí nabídky File. Data tak v případě potřeby zpracujete i v jiných aplikacích.
Jak extrahovat data z webových stránek
Na kartě Settings vám Greeflare nabízí zapnutí kontroly značek title, meta description, h1 a h2. Pokud byste rádi získali obsah jiných prvků na stránce, přidali jej do tabulky s výsledky procházení webu a pak jej třeba exportovali do CSV, přepněte se na kartu Extractions.
To je totiž místo, kde pomocí CSS selektoru nebo XPath specifikujete prvek, jehož obsah má Greeflare zařadit do reportu. Pokud není CSS selektor jednoznačný, pak se do reportu vloží obsah prvního nalezeného prvku. Rovněž dojde k odebrání HTML značek z tohoto prvku.
Získaná data jsou zobrazena v posledních sloupečcích kontrolního reportu. Extrakcí si samozřejmě připravíte, kolik potřebujete. Jednoduše tak lze získat třeba jména autorů článků, data publikace nebo informace o vyplněných značkách OpenGraph pro sociální sítě.
Jakkoli je totiž specifikace CSS selektorem pohodlná, Greenflare vás na ni neomezuje a nabízí rovněž možnost specifikovat prvek pomocí XPath. Díky tomu extrahujete úplně cokoli, od značky po hodnotu nějakého atributu kdekoli na stránce.
Jak jsem Greenflare využil v praxi
Nedávno jeden klient zjistil, že na webu s více mezinárodními verzemi si nakopíroval německou stránku pro rakouský a švýcarský trh. Všechny tři verze webu jsou německy, ale některé stránky se mírně liší. Klient následně zjistil, že některé odkazy na stránkách vedou i z jiných německy psaných verzí na další německé adresy, přitom by měly zachovat svou doménu. Bylo tedy třeba najít, kde se v textu vyskytují ručně zapsané odkazy směřující na konkrétní AT a CH doménu.
Marketingová a SEO agentura si s tím bohužel neporadila. Netuším, jaký používají scrapper, ale našel jim jako problémové úplně všechny stránky - jistě, byl v jich přepínač jazyků, který na AT a CH vede. Můj první nápad sice byl, že si napíšu vlastní udělátko v Pythonu nebo R, ale pak jsem si vzpomněl, že Greenflare umí extrahovat prvky ve stránce.
Zadal jsem tedy zdrojovou doménu, na kartě Extraction jsem doplnil CSS selektor main a[href^="https://www.nejakadomena.at"] (tedy odkazy začínající danou doménou, ale je v obsahové části každé stránky na webu), spustil scrapování a za chvíli měl výsledky. Tam, kde se ve sloupečku s extrakcí objevily výsledky, jsme obsah zeditoval a poté kontrolu webu pomocí Greenflare provedl ještě jednou. Je to snadné a bez programování.

Tvůrce webů z Brna se specializací na Drupal, WordPress a Symfony. Acquia Certified Developer & Site Builder. Autor několika knih o Drupalu.
Web Development Director v Lesensky.cz. Ve volných chvílích podnikám výlety na souši i po vodě. Více se dozvíte na polzer.cz a mém LinkedIn profilu.








Přidat komentář